\(~~~~~~~~~\)Probability and Statistics\(~~~~~~~~~\)
หัวข้อสถิติ
อ.ดร. สมศักดิ์ จันทร์เอม
วิทยาลัยนานาชาตินวัตกรรมดิจิทัล มหาวิทยาลัยเชียงใหม่
31 มีนาคม 2569
ทำไมต้องใช้สถิติ?
The “Why”
มองเห็นสิ่งที่ซ่อนอยู่ในตัวเลข 🔍
สถิติ (Statistics)
สถิติ คือ ศาสตร์แห่งการเก็บรวบรวม วิเคราะห์ แปลผล และนำเสนอข้อมูล เพื่อสนับสนุนการตัดสินใจ หรือเพื่อทำความเข้าใจปรากฏการณ์ต่าง ๆ ได้ดียิ่งขึ้น
สถิติมีอยู่สองสาขาหลัก ได้แก่
- สถิติเชิงพรรณนา (Descriptive Statistics)
- สถิติอนุมาน (Inferential Statistics)
การประยุกต์ใช้ทางสถิติ (Applications)
1. ธุรกิจและการเงิน (Business & Finance)
พยากรณ์ยอดขาย (Forecasting)
ประเมินความเสี่ยงพอร์ตการลงทุน (Risk Analysis)
2. วิทยาศาสตร์ข้อมูล (Data Science & AI)
วิเคราะห์ข้อมูลขนาดใหญ่ (Big Data)
สร้างโมเดลทำนายผล (Machine Learning)
3. การแพทย์และวิจัย (Medicine & Research)
ทดสอบประสิทธิภาพวัคซีน (A/B Testing)
วิเคราะห์การระบาดของโรค
ปัญหาของ “ข้อมูลดิบ” (Raw Data)
สมมติคุณเป็นผู้บริหาร แล้วลูกน้องส่งรายงานยอดขายมาแบบนี้:
| สาขา | ม.ค. | ก.พ. | มี.ค. | … | ธ.ค. |
|---|---|---|---|---|---|
| A | 120 | 135 | 110 | … | 190 |
| B | 500 | 20 | 50 | … | 800 |
| C | 300 | 305 | 295 | … | 310 |
| … | … | … | … | … | … |
คำถาม: สาขาไหน “ผลงานดีที่สุด”? และสาขาไหน “น่าเป็นห่วง”?
คำตอบ: ดูไม่ออก! เพราะข้อมูลเยอะเกินไป (Information Overload)
เราจึงต้องการ “ตัวเลขตัวแทน” (Descriptive Statistics) มาสรุปเรื่องราวทั้งหมด
การหาตัวแทนข้อมูล
The Representative
Mean vs Median 🥊
สถิติเชิงพรรณนา (Descriptive Statistics)
ใช้เพื่อ สรุปและอธิบายข้อมูล
ค่ากลาง: Mean, Median
การกระจาย: Variance, SD
รูปร่าง: Skewness, Kurtosis
ความสัมพันธ์: Pearson Correlation
ค่าเฉลี่ย (Mean or Average)
คำจำกัดความ (Definition):
ค่าเฉลี่ย (Mean) คือจุดกึ่งกลางของข้อมูล (Center of Gravity)
\[\bar{x}=\dfrac{1}{n}\sum_{i=1}^n x_i\]
\(\bar{x}\) = ค่าเฉลี่ย
\(x_i\) = ค่าของข้อมูลแต่ละตัว
\(n\) = จำนวนข้อมูลทั้งหมด
ตัวอย่าง: ข้อมูล 70, 80, 90, 85, 75
\[ \text { Mean }=\frac{70+80+90+85+75}{5}=\frac{400}{5}=80 \]
⚠️ กับดักของค่าเฉลี่ย (The Mean Trap)
ทำไมค่าเฉลี่ยถึงเชื่อไม่ได้เสมอไป?
สถานการณ์สมมติ: บาร์เหล้าและมหาเศรษฐี
ในบาร์มีคนนั่งอยู่ 5 คน มีรายได้เฉลี่ย 30,000 บาท/เดือน
จู่ๆ Bill Gates (หรือเจ้าสัวระดับโลก) เดินเข้ามาในบาร์…
ทันทีที่เขาเดินเข้ามา รายได้เฉลี่ยของคนในบาร์จะพุ่งเป็น “ร้อยล้านบาท” ทันที!
ถาม: ทุกคนในบาร์รวยขึ้นจริงหรือ?
ตอบ: ไม่จริง! แต่ ค่าเฉลี่ยถูกดึง (Distorted) โดยคนรวยเพียงคนเดียว (Outlier)
นี่คือเหตุผลที่เราต้องรู้จัก “มัธยฐาน (Median)”
ค่ามัธยฐาน (Median)
คำจำกัดความ:
ค่ามัธยฐาน (Median) คือ ค่าตรงกลาง เมื่อเรียงข้อมูลจากน้อยไปมาก
จุดเด่น:
ทนทานต่อค่าสุดโต่ง (Robust to Outliers)
เหมาะกับข้อมูลรายได้, ราคาบ้าน
🥊 Mean vs. Median Battle
viewof outlierGame = (function() {
const uid = "out_" + Math.random().toString(36).substr(2, 9);
const width = 600;
const height = 250;
// สร้าง Container
const container = html`<div style="font-family:'Sarabun', sans-serif; display:flex; flex-direction:column; align-items:center; gap:15px; background:white; padding:25px; border-radius:16px; border:1px solid #e2e8f0; box-shadow:0 4px 15px rgba(0,0,0,0.05); max-width:700px; margin:0 auto; user-select: none; -webkit-user-select: none;">
<div style="font-size:14px; color:#64748b; text-align:center;">
(วิธีแก้ใหม่) ลอง <b>คลิกค้างที่จุดแดง</b> แล้วลากได้เลยครับ (ลื่นกว่าเดิม)
</div>
<canvas width="${width}" height="${height}" style="background:#f8fafc; border-radius:8px; border:1px solid #cbd5e1; cursor:ew-resize; touch-action: none;"></canvas>
<div style="display:flex; gap:20px; width:100%; justify-content:center;">
<div style="text-align:center; padding:10px 20px; background:#dbeafe; border-radius:8px; color:#1e40af;">
<div style="font-size:12px;">ค่าเฉลี่ย (Mean)</div>
<div id="${uid}-val-mean" style="font-size:24px; font-weight:bold;">0</div>
<div style="font-size:10px;">(อ่อนไหวมาก)</div>
</div>
<div style="text-align:center; padding:10px 20px; background:#fce7f3; border-radius:8px; color:#9d174d;">
<div style="font-size:12px;">มัธยฐาน (Median)</div>
<div id="${uid}-val-median" style="font-size:24px; font-weight:bold;">0</div>
<div style="font-size:10px;">(ใจแข็ง/ทนทาน)</div>
</div>
</div>
</div>`;
const canvas = container.querySelector("canvas");
const ctx = canvas.getContext("2d");
const elMean = container.querySelector(`#${uid}-val-mean`);
const elMedian = container.querySelector(`#${uid}-val-median`);
// ข้อมูลเริ่มต้น
let points = [100, 120, 130, 140, 150];
let outlier = 160;
let isDragging = false;
const Y_POS = height / 2;
// ฟังก์ชันวาดและคำนวณ
function update() {
const allData = [...points, outlier].sort((a,b) => a-b);
// คำนวณ Mean
const sum = allData.reduce((a,b) => a+b, 0);
const mean = sum / allData.length;
// คำนวณ Median
let median = 0;
const mid = Math.floor(allData.length / 2);
if (allData.length % 2 === 0) {
median = (allData[mid-1] + allData[mid]) / 2;
} else {
median = allData[mid];
}
elMean.innerText = (mean).toFixed(1);
elMedian.innerText = (median).toFixed(1);
draw(mean, median);
}
function draw(mean, median) {
ctx.clearRect(0,0,width,height);
// เส้นแกน
ctx.beginPath();
ctx.moveTo(20, Y_POS);
ctx.lineTo(width-20, Y_POS);
ctx.strokeStyle = "#cbd5e1";
ctx.lineWidth = 2;
ctx.stroke();
// จุดปกติ (สีเทา)
ctx.fillStyle = "#94a3b8";
points.forEach(p => {
ctx.beginPath();
ctx.arc(p, Y_POS, 6, 0, Math.PI*2);
ctx.fill();
});
// จุด Outlier (สีแดง) - วาดให้ใหญ่หน่อยจะได้คลิกง่าย
ctx.fillStyle = "#ef4444";
ctx.beginPath();
ctx.arc(outlier, Y_POS, 12, 0, Math.PI*2); // เพิ่มขนาดจุดคลิก
ctx.fill();
ctx.strokeStyle = "white";
ctx.lineWidth = 2;
ctx.stroke();
// เส้น Mean (สีน้ำเงิน)
ctx.beginPath();
ctx.moveTo(mean, Y_POS - 30);
ctx.lineTo(mean, Y_POS + 30);
ctx.strokeStyle = "#2563eb";
ctx.lineWidth = 3;
ctx.setLineDash([5, 3]);
ctx.stroke();
ctx.setLineDash([]);
ctx.fillStyle = "#2563eb";
ctx.font = "12px sans-serif";
ctx.fillText("Mean", mean - 15, Y_POS - 35);
// เส้น Median (สีชมพู)
ctx.beginPath();
ctx.moveTo(median, Y_POS - 20);
ctx.lineTo(median, Y_POS + 20);
ctx.strokeStyle = "#db2777";
ctx.lineWidth = 3;
ctx.stroke();
ctx.fillStyle = "#db2777";
ctx.fillText("Median", median - 20, Y_POS + 35);
}
// --- Interaction Logic (แบบ Global Window) ---
// 1. กดลงที่ Canvas
canvas.addEventListener('pointerdown', (e) => {
const rect = canvas.getBoundingClientRect();
const x = e.clientX - rect.left;
// เช็คว่ากดโดนจุดแดงไหม (ให้ระยะกว้างๆ 30px)
if (Math.abs(x - outlier) < 30) {
isDragging = true;
e.preventDefault(); // กัน Seletion
// เทคนิคสำคัญ: ฝาก Event ไว้ที่ window แทน canvas
window.addEventListener('pointermove', onGlobalMove);
window.addEventListener('pointerup', onGlobalUp);
}
});
// 2. ขยับเมาส์ (ไม่ว่าจะอยู่ตรงไหนของจอ)
function onGlobalMove(e) {
if (!isDragging) return;
e.preventDefault();
// คำนวณตำแหน่งใหม่ โดยอ้างอิงจาก Canvas เสมอ
const rect = canvas.getBoundingClientRect();
let x = e.clientX - rect.left;
// จำกัดขอบเขตไม่ให้หลุดจอ
if (x < 20) x = 20;
if (x > width-20) x = width-20;
outlier = x;
update();
}
// 3. ปล่อยเมาส์
function onGlobalUp(e) {
isDragging = false;
// ลบ Event ออกจาก window เพื่อคืนทรัพยากร
window.removeEventListener('pointermove', onGlobalMove);
window.removeEventListener('pointerup', onGlobalUp);
}
// เริ่มต้นวาดครั้งแรก
update();
return container;
})()ความเสี่ยงและความผันผวน
Risk & Variability
📉 〰️ 📈
🍜 ร้านอาหาร 2 ร้าน: ค่าเฉลี่ยเท่ากัน แต่ไม่เหมือนกัน
ร้าน A (สม่ำเสมอ)
⭐⭐⭐
⭐⭐⭐
⭐⭐⭐
⭐⭐⭐
⭐⭐⭐
Mean: 3.0
ความรู้สึก: “พอกินได้” ตลอดเวลา (Safe Choice)
ร้าน B (ผีเข้าผีออก)
⭐⭐⭐⭐⭐ (อร่อยเหาะ)
⭐ (กินไม่ได้)
⭐⭐⭐⭐⭐
⭐
⭐⭐⭐
- Mean: 3.0
- ความรู้สึก: “วัดดวง” (Risky Choice)
สถิติที่ใช้วัดความ “ผีเข้าผีออก” นี้เรียกว่า ความแปรปรวน (Variance)
ความแปรปรวน (Variance)
คำจำกัดความ (Definition):
ความแปรปรวน (Variance) ใช้วัด การกระจายตัว (Spread) ของข้อมูล
ค่าต่ำ: ข้อมูลเกาะกลุ่ม (ร้าน A)
ค่าสูง: ข้อมูลกระจัดกระจาย (ร้าน B)
\[ s^2=\frac{1}{n-1} \sum_{i=1}^n\left(x_i-\bar{x}\right)^2 \]
ทำไม Variance ถึงพังเมื่อเจอ Outlier?
viewof varianceDemo = (function() {
const uid = "var_demo_" + Math.random().toString(36).substr(2, 9);
const width = 700;
const height = 300;
const container = html`<div style="font-family:'Sarabun', sans-serif; display:flex; flex-direction:column; align-items:center; gap:20px; background:white; padding:25px; border-radius:16px; border:1px solid #e2e8f0; box-shadow:0 4px 15px rgba(0,0,0,0.05); max-width:750px; margin:0 auto;">
<div style="font-size:14px; color:#64748b; text-align:center;">
ลองลาก <b>จุดสีแดง (Outlier)</b> ไปทางขวาสุดๆ<br>
สังเกตว่า <b>SD (พื้นที่แดง)</b> พยายามจะครอบคลุมมัน จนเสียทรง<br>
แต่ <b>IQR (พื้นที่เขียว)</b> ไม่แคร์เลย
</div>
<div style="position:relative;">
<canvas width="${width}" height="${height}" style="background:#f8fafc; border-radius:8px; border:1px solid #cbd5e1; cursor:ew-resize;"></canvas>
</div>
<div style="display:flex; gap:20px; font-size:12px;">
<div style="display:flex;
align-items:center; gap:5px;">
<div style="width:15px; height:15px; background:rgba(239, 68, 68, 0.2);
border:1px solid #ef4444;"></div>
<span style="color:#b91c1c;
font-weight:bold;">Variance/SD (Sensitive)</span>
</div>
<div style="display:flex; align-items:center;
gap:5px;">
<div style="width:15px; height:15px; background:rgba(34, 197, 94, 0.2);
border:1px solid #22c55e;"></div>
<span style="color:#15803d;
font-weight:bold;">IQR (Robust)</span>
</div>
</div>
<div style="width:100%; display:grid;
grid-template-columns: 1fr 1fr; gap:15px; background:#f1f5f9; padding:15px; border-radius:12px;">
<div style="color:#b91c1c;">
<div style="font-size:12px;">Standard Deviation (SD)</div>
<div id="${uid}-val-sd" style="font-size:24px;
font-weight:bold;">0</div>
<div style="font-size:10px;">(เปลี่ยนไปตามจุดแดง)</div>
</div>
<div style="color:#15803d;">
<div style="font-size:12px;">Interquartile Range (IQR)</div>
<div id="${uid}-val-iqr" style="font-size:24px;
font-weight:bold;">0</div>
<div style="font-size:10px;">(นิ่งสงบ สยบความเคลื่อนไหว)</div>
</div>
</div>
</div>`;
const canvas = container.querySelector("canvas");
const ctx = canvas.getContext("2d");
const elSD = container.querySelector(`#${uid}-val-sd`);
const elIQR = container.querySelector(`#${uid}-val-iqr`);
// Data
let points = [40, 42, 45, 48, 50, 52, 55, 58, 60]; // Normal group
let outlier = 70; // Start near group
let isDragging = false;
function getStats(data) {
const n = data.length;
const mean = data.reduce((a,b)=>a+b,0)/n;
const variance = data.reduce((a,b)=>a + Math.pow(b-mean, 2), 0) / (n-1);
const sd = Math.sqrt(variance);
const sorted = [...data].sort((a,b)=>a-b);
const q1 = sorted[Math.floor((n-1)*0.25)];
const q3 = sorted[Math.floor((n-1)*0.75)];
const iqr = q3 - q1;
const median = sorted[Math.floor((n-1)*0.5)];
return { mean, sd, median, q1, q3, iqr };
}
function draw() {
const allData = [...points, outlier];
const stats = getStats(allData);
elSD.innerText = stats.sd.toFixed(2);
elIQR.innerText = stats.iqr.toFixed(2);
ctx.clearRect(0,0,width,height);
// Scale: map 0-200 to canvas
const scaleX = (val) => (val / 200) * width;
const yCenter = height / 2;
// 1. Draw SD Range (Red Zone)
// Mean - SD to Mean + SD
const sdLeft = scaleX(stats.mean - stats.sd);
const sdRight = scaleX(stats.mean + stats.sd);
ctx.fillStyle = "rgba(239, 68, 68, 0.15)";
ctx.fillRect(sdLeft, yCenter - 60, sdRight - sdLeft, 120);
ctx.strokeStyle = "#ef4444";
ctx.lineWidth = 1;
ctx.strokeRect(sdLeft, yCenter - 60, sdRight - sdLeft, 120);
// Mean Line
ctx.beginPath();
ctx.moveTo(scaleX(stats.mean), yCenter - 60);
ctx.lineTo(scaleX(stats.mean), yCenter + 60);
ctx.setLineDash([5,5]);
ctx.stroke();
ctx.setLineDash([]);
ctx.fillStyle = "#b91c1c";
ctx.font = "12px sans-serif";
ctx.fillText("Mean", scaleX(stats.mean)-15, yCenter - 65);
// 2. Draw IQR Range (Green Zone)
// Q1 to Q3 (Usually narrower)
const iqrLeft = scaleX(stats.q1);
const iqrRight = scaleX(stats.q3);
ctx.fillStyle = "rgba(34, 197, 94, 0.3)";
// Darker green
ctx.fillRect(iqrLeft, yCenter - 30, iqrRight - iqrLeft, 60);
ctx.strokeStyle = "#16a34a";
ctx.lineWidth = 2;
ctx.strokeRect(iqrLeft, yCenter - 30, iqrRight - iqrLeft, 60);
// Median Line
ctx.beginPath();
ctx.moveTo(scaleX(stats.median), yCenter - 30);
ctx.lineTo(scaleX(stats.median), yCenter + 30);
ctx.strokeStyle = "#16a34a";
ctx.lineWidth = 3;
ctx.stroke();
ctx.fillStyle = "#16a34a";
ctx.fillText("Median", scaleX(stats.median)-20, yCenter + 45);
// 3. Draw Points
// Normal Points
ctx.fillStyle = "#3b82f6";
points.forEach(p => {
ctx.beginPath();
ctx.arc(scaleX(p), yCenter, 5, 0, Math.PI*2);
ctx.fill();
});
// Outlier Point
ctx.fillStyle = "#dc2626";
ctx.beginPath();
ctx.arc(scaleX(outlier), yCenter, 8, 0, Math.PI*2);
ctx.fill();
ctx.strokeStyle = "white";
ctx.lineWidth = 2;
ctx.stroke();
ctx.fillStyle = "#dc2626";
ctx.fillText("Outlier", scaleX(outlier)-15, yCenter - 15);
// Axis
ctx.beginPath();
ctx.moveTo(0, height-20);
ctx.lineTo(width, height-20);
ctx.strokeStyle = "#94a3b8";
ctx.stroke();
}
// Interactions
canvas.onmousedown = (e) => {
const rect = canvas.getBoundingClientRect();
const x = e.clientX - rect.left;
const val = (x / width) * 200;
if (Math.abs(val - outlier) < 10) isDragging = true;
};
window.addEventListener("mousemove", (e) => {
if(!isDragging) return;
const rect = canvas.getBoundingClientRect();
let x = e.clientX - rect.left;
let val = (x / width) * 200;
if (val < 0) val = 0; if (val > 200) val = 200;
outlier = val;
draw();
});
window.addEventListener("mouseup", () => isDragging = false);
draw();
return container;
})()ส่วนเบี่ยงเบนมาตรฐาน (Standard Deviation)
คำจำกัดความ (Definition):
ส่วนเบี่ยงเบนมาตรฐาน (SD) คือรากที่สองของความแปรปรวน
\[ s=\sqrt{\text { Variance }} \]
ทำไมต้องถอดราก?
เพื่อให้หน่วยกลับมาเป็นหน่วยเดิม (เช่น “บาท” แทนที่จะเป็น “บาท²”)
ทำให้ตีความและเปรียบเทียบง่ายขึ้น
รูปร่างของข้อมูล
The Shape of Data
Skewness & Kurtosis 🦕
ความเบ้ (Skewness)
คำจำกัดความ:
ใช้วัด ความไม่สมมาตร (เอียงซ้าย/เอียงขวา)
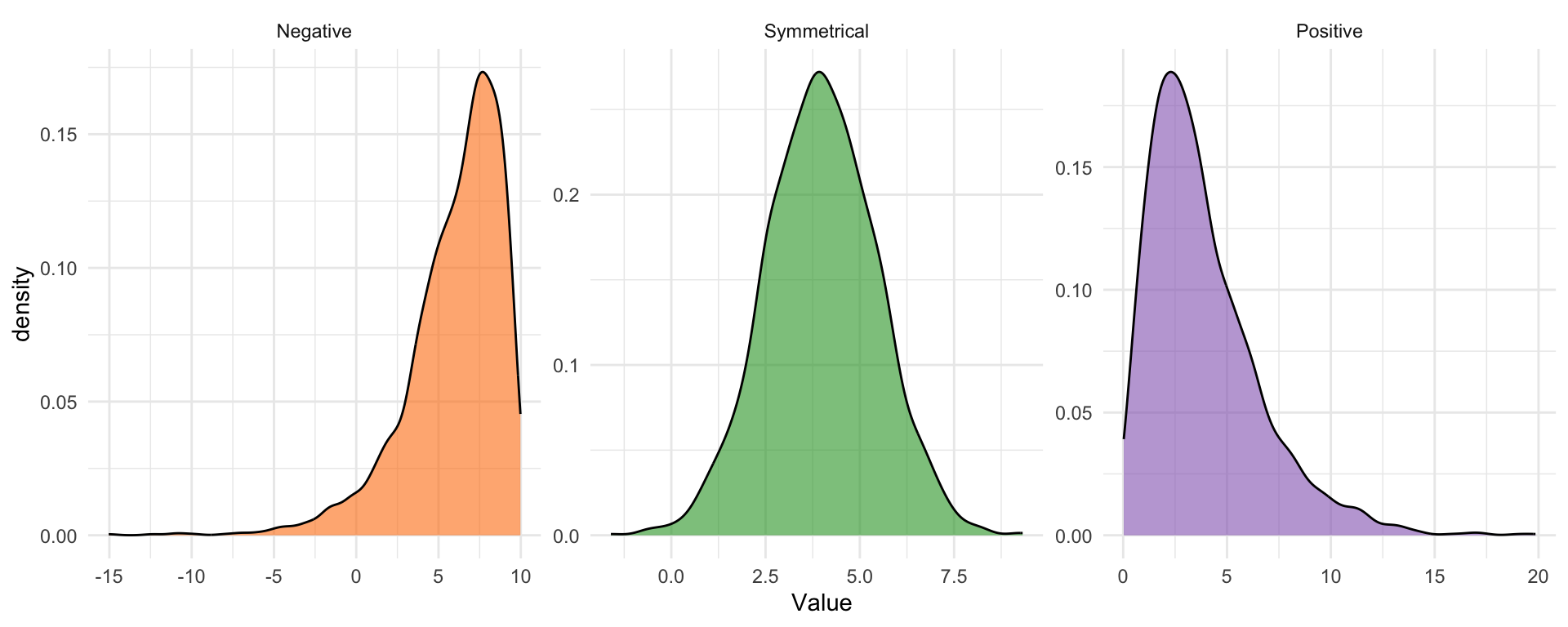
ค่าความเบ้เป็นลบ (Negative / Left Skewed): เบ้ซ้าย หางกราฟยาวไปทางซ้าย ข้อมูลส่วนใหญ่กองอยู่ทางขวา (Mean < Median)
ค่าความเบ้ = 0 (Symmetrical): ข้อมูลมีการกระจายตัวแบบสมมาตร (รูประฆังคว่ำปกติ)
ค่าความเบ้เป็นบวก (Positive / Right Skewed): เบ้ขวา หางกราฟยาวไปทางขวา ข้อมูลส่วนใหญ่กองอยู่ทางซ้าย (Mean > Median)
ความโด่ง (Kurtosis)
คำจำกัดความ:
ใช้วัด ความอ้วน/ผอม ของหางกราฟ (มี Outlier เยอะไหม?)
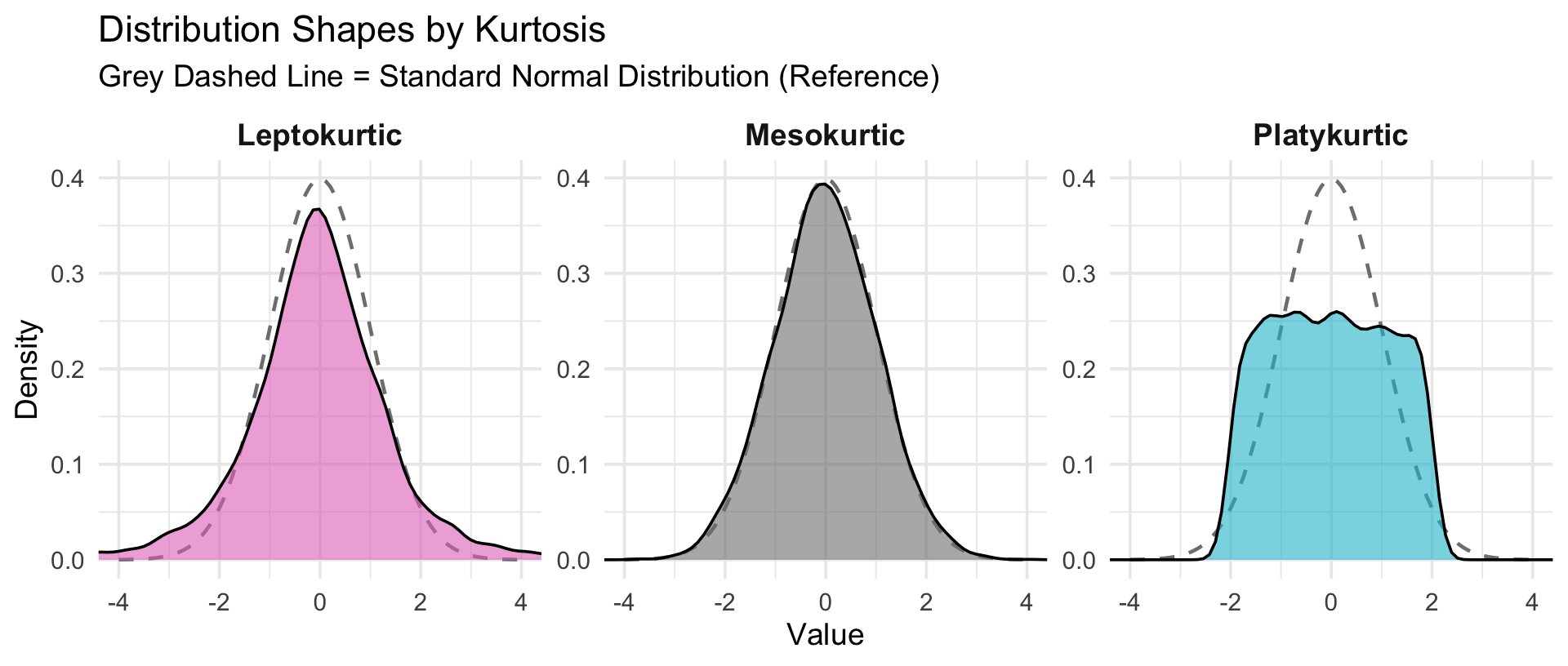
Leptokurtic (ค่า > 3 หรือ Excess > 0): โด่งมาก (สูงแหลม) หางกราฟหนา (Fat Tails) มีโอกาสเกิดค่าสุดโต่ง (Outliers) สูง
Mesokurtic (ค่า = 3 หรือ Excess = 0): โด่งปกติ การแจกแจงเหมือน Normal Distribution
Platykurtic (ค่า < 3 หรือ Excess < 0): โด่งน้อย (แบนราบ) หางกราฟบาง ข้อมูลกระจายตัวสม่ำเสมอ ไม่ค่อยมีค่าสุดโต่ง
📊 Distribution Lab (Beta Distribution)
viewof betaDistCorrected = (function() {
const uid = "beta_fixed_" + Math.random().toString(36).substr(2, 9);
const width = 700;
const height = 400;
const container = html`<div style="font-family:'Sarabun', sans-serif; display:flex; flex-direction:column; align-items:center; gap:15px; background:white; padding:20px; border-radius:16px; border:1px solid #e2e8f0; box-shadow:0 4px 15px rgba(0,0,0,0.05); max-width:750px; margin:0 auto;">
<div style="font-size:13px; color:#64748b; text-align:center;">
ปรับค่า Alpha/Beta เพื่อดูความเบ้ (Skewness) และความโด่ง (Kurtosis)
</div>
<div style="position:relative;">
<canvas width="${width}" height="${height}" style="background:#f8fafc; border-radius:8px; border:1px solid #cbd5e1;"></canvas>
<div style="position:absolute; top:10px; right:10px; background:rgba(255,255,255,0.95); padding:10px; border-radius:8px; border:1px solid #94a3b8; font-size:12px; box-shadow:0 2px 10px rgba(0,0,0,0.1);">
<div style="margin-bottom:5px;
font-weight:bold; color:#1e293b; border-bottom:1px solid #e2e8f0; padding-bottom:3px;">Statistics Legend</div>
<div style="display:grid;
grid-template-columns: auto auto; gap:3px 10px;">
<div style="color:#dc2626;
font-weight:bold;">Mean (เฉลี่ย):</div>
<div id="${uid}-val-mean" style="text-align:right;">-</div>
<div style="color:#2563eb;
font-weight:bold;">Median (มัธยฐาน):</div>
<div id="${uid}-val-median" style="text-align:right;">-</div>
<div style="color:#059669;">SD (ส่วนเบี่ยงเบน):</div>
<div id="${uid}-val-sd" style="text-align:right;">-</div>
<div style="color:#7c3aed;
font-weight:bold;">Skewness (เบ้):</div>
<div id="${uid}-val-skew" style="text-align:right; font-weight:bold;
color:#7c3aed;">-</div>
<div style="color:#db2777;
font-weight:bold;">Kurtosis (โด่ง):</div>
<div id="${uid}-val-kurt" style="text-align:right; font-weight:bold;
color:#db2777;">-</div>
</div>
</div>
</div>
<div style="width:100%;
display:grid; grid-template-columns: 1fr 1fr; gap:15px; background:#f1f5f9; padding:15px; border-radius:12px;">
<div>
<div style="display:flex;
justify-content:space-between; align-items:center; margin-bottom:2px;">
<span style="font-weight:bold; color:#334155; font-size:12px;
white-space:nowrap;">Parameter α (Alpha)</span>
<span id="${uid}-disp-a" style="font-weight:bold; color:#2563eb;
font-size:12px;">2.0</span>
</div>
<input id="${uid}-sl-a" type="range" min="0.5" max="10" value="2" step="0.1" style="width:100%;
accent-color:#4338ca; margin:5px 0;">
<div style="font-size:10px; color:#64748b;
white-space:nowrap;">(ค่าน้อย = ดันไปทางซ้าย/ขอบ)</div>
</div>
<div>
<div style="display:flex;
justify-content:space-between; align-items:center; margin-bottom:2px;">
<span style="font-weight:bold; color:#334155; font-size:12px;
white-space:nowrap;">Parameter β (Beta)</span>
<span id="${uid}-disp-b" style="font-weight:bold; color:#ea580c;
font-size:12px;">5.0</span>
</div>
<input id="${uid}-sl-b" type="range" min="0.5" max="10" value="5" step="0.1" style="width:100%;
accent-color:#4338ca; margin:5px 0;">
<div style="font-size:10px; color:#64748b;
white-space:nowrap;">(ค่าน้อย = ดันไปทางขวา/ขอบ)</div>
</div>
</div>
</div>`;
const canvas = container.querySelector("canvas");
const ctx = canvas.getContext("2d");
const slA = container.querySelector(`#${uid}-sl-a`);
const slB = container.querySelector(`#${uid}-sl-b`);
const dispA = container.querySelector(`#${uid}-disp-a`);
const dispB = container.querySelector(`#${uid}-disp-b`);
const elMean = container.querySelector(`#${uid}-val-mean`);
const elMedian = container.querySelector(`#${uid}-val-median`);
const elSD = container.querySelector(`#${uid}-val-sd`);
const elSkew = container.querySelector(`#${uid}-val-skew`);
const elKurt = container.querySelector(`#${uid}-val-kurt`);
function logGamma(z) {
const c = [57.1562356658629235, -59.5979603554754912,
14.1360979747417471, -0.491913816097620199, .339946499848118887e-4,
.465236289270485756e-4, -.980110293032623307e-5, .158088703224912494e-3,
-.249910353874351101e-2, .177454516771575316e-1, .754705354271336459,
.252012282494909806];
let sum = c[0];
for (let i = 1; i < c.length; i++) sum += c[i] / (z + i);
let g = (z + 0.5) * Math.log(z + 5.5) - (z + 5.5);
return g + Math.log(2.5066282746310005 * sum / z);
}
function betaPDF(x, a, b) {
if (x <= 0 || x >= 1) return 0;
const lnVal = logGamma(a + b) - logGamma(a) - logGamma(b) + (a - 1) * Math.log(x) + (b - 1) * Math.log(1 - x);
return Math.exp(lnVal);
}
function update() {
const a = parseFloat(slA.value);
const b = parseFloat(slB.value);
dispA.innerText = a.toFixed(1);
dispB.innerText = b.toFixed(1);
const mean = a / (a + b);
const variance = (a * b) / (Math.pow(a + b, 2) * (a + b + 1));
const sd = Math.sqrt(variance);
// Skewness
let skew = 0;
if (a !== b) skew = (2 * (b - a) * Math.sqrt(a + b + 1)) / ((a + b + 2) * Math.sqrt(a * b));
// Kurtosis
const num = 6 * (Math.pow(a - b, 2) * (a + b + 1) - (a * b * (a + b + 2)));
const den = (a * b * (a + b + 2) * (a + b + 3));
const kurt = num / den;
// --- 🔥 FIX: Accurate Median Approximation ---
// สูตร Groeneveld & Meeden (1977)
const median = (a - 1/3) / (a + b - 2/3);
const scale = 100;
elMean.innerText = (mean * scale).toFixed(2);
elMedian.innerText = (median * scale).toFixed(2);
elSD.innerText = (sd * scale).toFixed(2);
elSkew.innerText = skew.toFixed(3);
elKurt.innerText = kurt.toFixed(3);
if (skew > 0.1) elSkew.style.color = "#ea580c";
else if (skew < -0.1) elSkew.style.color = "#dc2626";
else elSkew.style.color = "#16a34a";
// Draw Graph
ctx.clearRect(0,0,width,height);
const pad = 40; const drawW = width - pad * 2; const drawH = height - pad * 2;
let maxY = 0; let points = [];
for(let i=0; i<=drawW; i++) {
const x = i / drawW;
const safeX = Math.max(0.001, Math.min(0.999, x));
const y = betaPDF(safeX, a, b);
if (y > maxY) maxY = y;
points.push({x: safeX, y: y});
}
if (maxY > 10) maxY = 10;
ctx.beginPath(); ctx.moveTo(pad, height - pad);
points.forEach((p) => {
const plotX = pad + (p.x * drawW); const plotY = (height - pad) - (p.y / maxY * drawH);
ctx.lineTo(plotX, plotY);
});
ctx.lineTo(pad + drawW, height - pad);
ctx.fillStyle = "rgba(99, 102, 241, 0.2)"; ctx.fill();
ctx.beginPath();
points.forEach((p, i) => {
const plotX = pad + (p.x * drawW); const plotY = (height - pad) - (p.y / maxY * drawH);
if (i===0) ctx.moveTo(plotX, plotY); else ctx.lineTo(plotX, plotY);
});
ctx.lineWidth = 3; ctx.strokeStyle = "#4f46e5"; ctx.stroke();
const drawLine = (val, color, label) => {
// Clamp val between 0 and 1
const safeVal = Math.max(0, Math.min(1, val));
const xPos = pad + (safeVal * drawW);
ctx.beginPath(); ctx.moveTo(xPos, pad); ctx.lineTo(xPos, height - pad);
ctx.strokeStyle = color;
ctx.lineWidth = 2;
ctx.setLineDash(label === "Median" ? [] : [5,5]); ctx.stroke(); ctx.setLineDash([]);
ctx.fillStyle = color; ctx.font = "bold 12px sans-serif";
ctx.fillText(label, xPos - 15, height - pad + 15);
const yAtVal = betaPDF(Math.max(0.001, Math.min(0.999, safeVal)), a, b);
const safeY = Math.min(yAtVal, maxY);
const yPos = (height - pad) - (safeY / maxY * drawH);
ctx.beginPath();
ctx.arc(xPos, yPos, 5, 0, Math.PI*2); ctx.fill();
};
drawLine(mean, "#dc2626", "Mean");
drawLine(median, "#2563eb", "Median");
ctx.beginPath(); ctx.moveTo(pad, height - pad);
ctx.lineTo(width - pad, height - pad);
ctx.strokeStyle = "#334155"; ctx.lineWidth = 1; ctx.stroke();
}
slA.oninput = update;
slB.oninput = update;
update();
return container;
})()การเปรียบเทียบมาตรฐาน
The Comparison
🍎 vs 🍊
🍎 เปรียบเทียบ “แอปเปิ้ล” กับ “ส้ม” ?
ปัญหาโลกแตกของการวิเคราะห์ข้อมูล คือ “หน่วยวัดไม่เหมือนกัน”
ใครเรียนเก่งกว่ากัน?
นักเรียน A: ได้เกรดเฉลี่ย (GPA) 3.8 (เต็ม 4.0)
นักเรียน B: ได้คะแนนสอบ SAT 1,450 (เต็ม 1,600)
เราเอา มาเทียบกับ ตรงๆ ไม่ได้! เราต้องแปลงทั้งคู่ให้เป็น “คะแนนมาตรฐาน” (Standardization) ก่อน เพื่อให้รู้ว่า “ใครอยู่เหนือกว่าค่าเฉลี่ยของกลุ่มตัวเองมากกว่ากัน”
Normalization vs Standardization
Normalization (Min-Max)
ปรับข้อมูลให้อยู่ในช่วง 0 ถึง 1
\[ x^{\prime}=\frac{x-x_{\min }}{x_{\max }-x_{\min }} \]
Standardization (Z-Score)
ปรับข้อมูลให้ Mean = 0, SD = 1
\[ z=\frac{x-\mu}{\sigma} \]
🔢 Scaling Calculator
viewof N22 = Inputs.range([10, 30], { step: 1, value: 20, label: "N (10–30)" })
// เลือกชนิดการสุ่มข้อมูล: จำนวนเต็ม หรือ ปกติ
viewof dist = Inputs.radio(["integer", "normal"], {label: "Distribution", value: "integer"})
// พารามิเตอร์ integer
viewof int_min = Inputs.number({label: "Integer min", value: 0, step: 1})
viewof int_max = Inputs.number({label: "Integer max", value: 100, step: 1})
// พารามิเตอร์ normal
viewof mu00 = Inputs.number({label: "Normal mean (μ)", value: 50, step: 0.1})
viewof sigma00 = Inputs.number({label: "Normal sd (σ)", value: 10, step: 0.1})
// ปุ่มจำลองข้อมูล
viewof simulate = Inputs.button("Simulate")
// ฟังก์ชันช่วยใน OJS
round2 = x => Math.round(x * 100) / 100
// Box–Muller สำหรับ N(0,1)
randn = () => {
let u = 0,
v = 0
while (u === 0) u = Math.random()
while (v === 0) v = Math.random()
return Math.sqrt(-2 * Math.log(u)) * Math.cos(2 * Math.PI * v)
}
// original: ออกผลเป็นอาร์เรย์ JS (จะถูกส่งต่อให้ R ผ่าน #| input:)
original = {
simulate;
// ให้รีรันเมื่อกดปุ่ม
if (dist === "integer") {
const lo = Math.min(int_min, int_max)
const hi = Math.max(int_min, int_max)
return Array.from({length: N22}, () =>
Math.floor(Math.random() * (hi - lo + 1)) + lo
)
} else {
return Array.from({length: N22}, () =>
round2(mu00 + sigma00 * randn())
)
}
}ความสัมพันธ์และการตัดสินใจ
Relationships & Decisions
🤝 🧠 🏆
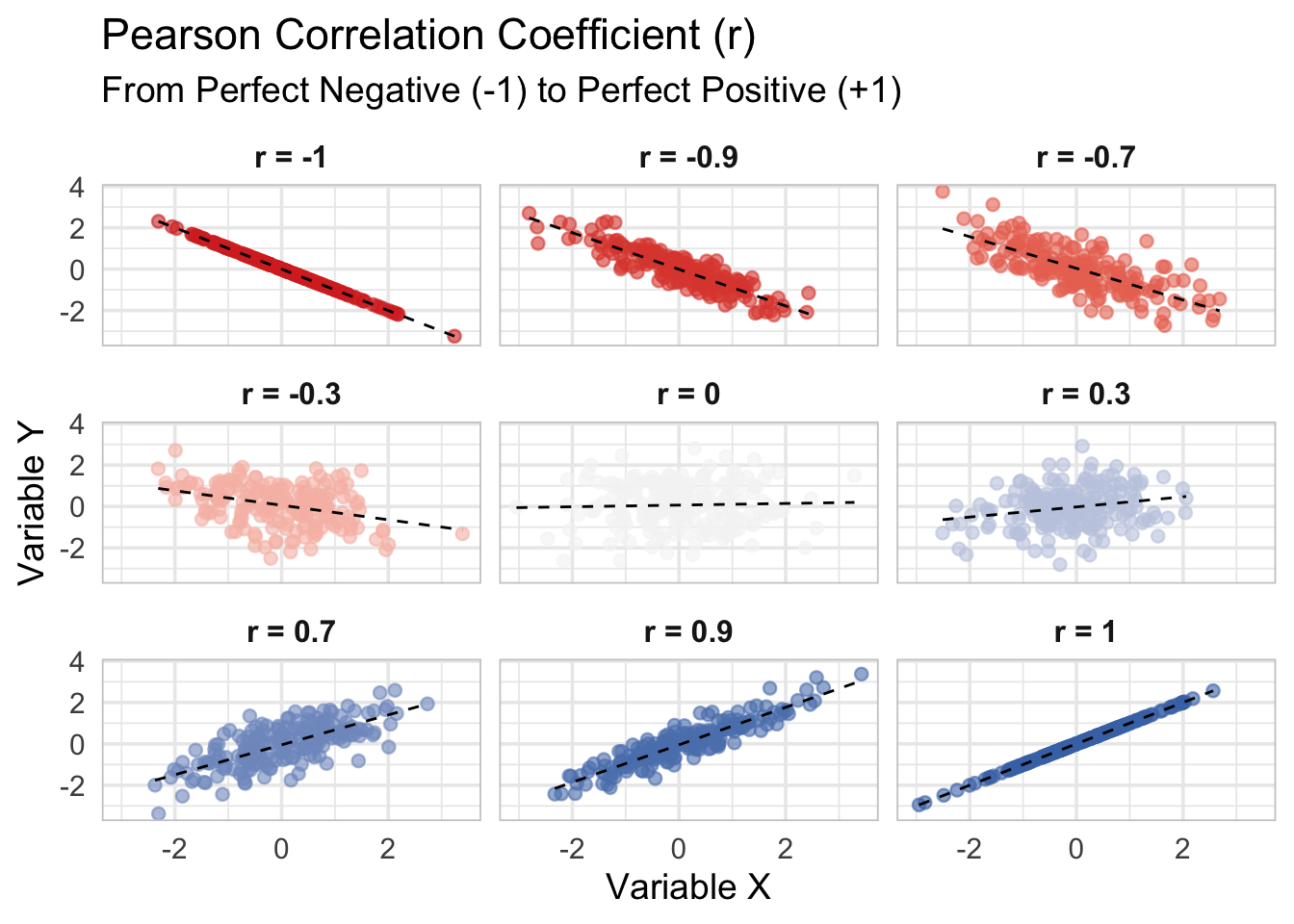
สหสัมพันธ์ของเพียร์สัน (Pearson Correlation)
ใช้วัด ความสัมพันธ์เชิงเส้น ระหว่างตัวแปรสองตัว (\(r\))
| ค่า \(r\) | ความหมาย |
|---|---|
| +1 | ไปทางเดียวกันเป๊ะ (Perfect Positive) |
| 0 | ไม่เกี่ยวข้องกันเลย (No Correlation) |
| -1 | ตรงข้ามกันเป๊ะ (Perfect Negative) |
สูตรการคำนวณ (Formula)
\[ r = \frac{\sum (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum (x_i - \bar{x})^2} \cdot \sqrt{\sum (y_i - \bar{y})^2}} \]
โดยที่:
- \(x_i, y_i\) = ค่าของตัวแปรทั้งสอง
- \(\bar{x}, \bar{y}\) = ค่าเฉลี่ยของแต่ละตัวแปร
🧐 Guess the Correlation
viewof guessCorr = (function() {
const uid = "corr_" + Math.random().toString(36).substr(2, 9);
const size = 400;
const container = html`<div style="font-family:'Sarabun', sans-serif; display:flex; flex-direction:column; align-items:center; gap:15px; background:white; padding:25px; border-radius:16px; border:1px solid #e2e8f0; box-shadow:0 4px 15px rgba(0,0,0,0.05); max-width:600px; margin:0 auto;">
<div style="font-size:14px; color:#64748b;">ทายซิว่าค่า r ของกราฟนี้คือเท่าไหร่?</div>
<div style="position:relative;">
<canvas width="${size}" height="${size}" style="background:#f8fafc; border-radius:8px; border:1px solid #cbd5e1;"></canvas>
</div>
<div id="${uid}-play-area" style="display:flex; flex-direction:column; gap:15px; width:100%; align-items:center;">
<div style="display:flex; align-items:center; gap:10px; width:100%; max-width:400px;">
<span style="font-weight:bold;
color:#475569;">0</span>
<input id="${uid}-slider" type="range" min="0" max="100" value="50" style="flex:1; accent-color:#4f46e5;
cursor:pointer;">
<span style="font-weight:bold;
color:#475569;">1</span>
</div>
<div style="font-size:18px;
font-weight:bold; color:#4f46e5;">
คำตอบของคุณ: <span id="${uid}-guess-val">0.50</span>
</div>
<button id="${uid}-btn-submit" style="background:#4f46e5;
color:white; border:none; padding:10px 40px; border-radius:50px; font-weight:bold; cursor:pointer; font-size:16px; box-shadow:0 4px 10px rgba(79, 70, 229, 0.3);">
✅ ส่งคำตอบ
</button>
</div>
<div id="${uid}-result-area" style="display:none;
flex-direction:column; align-items:center; gap:10px; width:100%; background:#f0fdf4; padding:15px; border-radius:12px; border:1px solid #bbf7d0;">
<div style="font-size:16px;
color:#166534;">
เฉลย: <b>r = <span id="${uid}-true-val"></span></b>
</div>
<div id="${uid}-feedback" style="font-size:20px;
font-weight:800;"></div>
<div id="${uid}-diff" style="font-size:14px;
color:#15803d;"></div>
<button id="${uid}-btn-next" style="background:#166534; color:white; border:none;
padding:8px 24px; border-radius:50px; font-weight:bold; cursor:pointer; margin-top:10px;">
➡️ ข้อต่อไป
</button>
</div>
<div style="display:flex;
gap:20px; font-size:14px; color:#64748b; margin-top:10px;">
<div>❤️ พลังชีวิต: <b id="${uid}-lives" style="color:#ef4444;">3</b></div>
<div>⭐ คะแนน: <b id="${uid}-score" style="color:#f59e0b;">0</b></div>
</div>
</div>`;
const canvas = container.querySelector("canvas");
const ctx = canvas.getContext("2d");
const slider = container.querySelector(`#${uid}-slider`);
const guessDisplay = container.querySelector(`#${uid}-guess-val`);
const btnSubmit = container.querySelector(`#${uid}-btn-submit`);
const btnNext = container.querySelector(`#${uid}-btn-next`);
const playArea = container.querySelector(`#${uid}-play-area`);
const resultArea = container.querySelector(`#${uid}-result-area`);
const elTrueVal = container.querySelector(`#${uid}-true-val`);
const elFeedback = container.querySelector(`#${uid}-feedback`);
const elDiff = container.querySelector(`#${uid}-diff`);
const elLives = container.querySelector(`#${uid}-lives`);
const elScore = container.querySelector(`#${uid}-score`);
let trueR = 0;
let score = 0;
let lives = 3;
let points = [];
function generateData() {
// Random r between 0.3 and 0.99 (easier range)
trueR = (Math.random() * 0.7 + 0.3).toFixed(2);
points = [];
const n = 200;
for(let i=0; i<n; i++) {
let x = rnorm();
let e = rnorm();
let y = trueR * x + Math.sqrt(1 - trueR*trueR) * e;
points.push({x, y});
}
draw();
}
function rnorm() {
let u = 0, v = 0;
while(u === 0) u = Math.random();
while(v === 0) v = Math.random();
return Math.sqrt( -2.0 * Math.log( u ) ) * Math.cos( 2.0 * Math.PI * v );
}
function draw() {
ctx.clearRect(0,0,size,size);
ctx.fillStyle = "#4f46e5";
// Scale points to canvas
// Find ranges roughly -3 to 3
const scale = size / 8;
const center = size / 2;
points.forEach(p => {
const px = center + p.x * scale;
const py = center - p.y * scale; // invert Y
ctx.beginPath();
ctx.arc(px, py, 3, 0, Math.PI*2);
ctx.fill();
});
}
// --- Logic ---
slider.oninput = () => {
guessDisplay.innerText = (slider.value / 100).toFixed(2);
};
btnSubmit.onclick = () => {
const guess = parseFloat(slider.value) / 100;
const actual = parseFloat(trueR);
const diff = Math.abs(guess - actual);
playArea.style.display = "none";
resultArea.style.display = "flex";
elTrueVal.innerText = actual.toFixed(2);
elDiff.innerText = `(คลาดเคลื่อน ${diff.toFixed(2)})`;
if (diff <= 0.05) {
elFeedback.innerText = "🎯 แม่นยำมาก!! (+10)";
elFeedback.style.color = "#166534";
score += 10;
} else if (diff <= 0.10) {
elFeedback.innerText = "👍 ใช้ได้ (+5)";
elFeedback.style.color = "#15803d";
score += 5;
} else {
elFeedback.innerText = "💥 ห่างไกลไปนิด (-1 ใจ)";
elFeedback.style.color = "#dc2626";
resultArea.style.background = "#fef2f2";
resultArea.style.borderColor = "#fca5a5";
lives--;
}
elScore.innerText = score;
elLives.innerText = lives;
if (lives <= 0) {
btnNext.innerText = "☠️ จบเกม (เริ่มใหม่)";
btnNext.style.background = "#dc2626";
btnNext.onclick = resetGame;
}
};
btnNext.onclick = nextRound;
function nextRound() {
playArea.style.display = "flex";
resultArea.style.display = "none";
resultArea.style.background = "#f0fdf4"; // reset color
resultArea.style.borderColor = "#bbf7d0";
slider.value = 50;
guessDisplay.innerText = "0.50";
generateData();
}
function resetGame() {
lives = 3;
score = 0;
elScore.innerText = 0;
elLives.innerText = 3;
btnNext.innerText = "➡️ ข้อต่อไป";
btnNext.style.background = "#166534";
btnNext.onclick = nextRound;
nextRound();
}
generateData();
return container;
})()💡 ตัวอย่างความสัมพันธ์ในชีวิตจริง
“ยิ่งมาก… ยิ่งดี”
เวลาอ่านหนังสือ ⬆️ คะแนนสอบ ⬆️
ส่วนสูง ⬆️ น้ำหนัก ⬆️
อุณหภูมิ ⬆️ ยอดขายไอติม ⬆️
“ยิ่งมาก… ยิ่งน้อย”
ความเร็วรถ ⬆️ เวลาเดินทาง ⬇️
ราคาสินค้า ⬆️ ยอดขาย ⬇️
ขาดเรียน ⬆️ เกรดเฉลี่ย ⬇️
“ไม่เกี่ยวกันเลย”
เบอร์รองเท้า ↔︎️ ความฉลาด (IQ)
ราคาทอง ↔︎️ ฝนตก
เลขบัตร ปชช. ↔︎️ เกรด
ตัวอย่างการประยุกต์
เกณฑ์ค่าเฉลี่ย–ความแปรปรวน (Mean-Variance Criteria)
กฎการตัดสินใจเลือกสิ่งที่ดีที่สุด (เช่น กองทุนหุ้น):
Mean (ผลตอบแทน): ยิ่งมากยิ่งดี 📈
Variance (ความเสี่ยง): ยิ่งน้อยยิ่งดี 📉
ถ้า A กำไรมากกว่า B และเสี่ยงน้อยกว่า B … เลือก A ทันที!
ถ้า B กำไรมากกว่า A และเสี่ยงน้อยกว่า A … เลือก B ทันที!
นอกจากนี้ ตัดสินใจไม่ได้
💼 Mean-Variance Decision Simulator
viewof mvGamePerfect = (function() {
const uid = "mv_perfect_" + Math.random().toString(36).substr(2, 9);
const width = 700;
const height = 350;
const container = html`<div style="font-family:'Sarabun', sans-serif; display:flex; flex-direction:column; align-items:center; gap:20px; background:white; padding:25px; border-radius:16px; border:1px solid #e2e8f0; box-shadow:0 4px 15px rgba(0,0,0,0.05); max-width:750px; margin:0 auto;">
<div style="font-size:14px; color:#64748b; text-align:center;">
เปรียบเทียบ 2 การลงทุน: กราฟไหน "คุ้มค่า" กว่ากัน (ขึ้นอยู่กับว่าลูกค้า? <b>"กลัวความเสี่ยง"</b> แค่ไหน)
</div>
<div style="position:relative;">
<canvas width="${width}" height="${height}" style="background:#f8fafc; border-radius:8px; border:1px solid #cbd5e1;"></canvas>
<div style="position:absolute;
bottom:5px; right:10px; font-size:12px; color:#64748b;">Return (%) ➡️</div>
</div>
<div style="width:100%; display:grid; grid-template-columns: 1fr 1fr;
gap:20px; background:#f1f5f9; padding:15px; border-radius:12px;">
<div style="border-right:1px solid #cbd5e1;
padding-right:15px;">
<div style="color:#2563eb; font-weight:bold; margin-bottom:10px;
white-space:nowrap;">🔵 กองทุน A (Blue)</div>
<div style="display:flex;
justify-content:space-between; font-size:12px;">
<span>Mean (กำไร): <b id="${uid}-val-ma">8</b>%</span>
</div>
<input id="${uid}-sl-ma" type="range" min="0" max="25" value="8" step="0.5" style="width:100%;
accent-color:#2563eb;">
<div style="display:flex; justify-content:space-between; font-size:12px;
margin-top:5px;">
<span>Risk (SD): <b id="${uid}-val-sa">2</b>%</span>
</div>
<input id="${uid}-sl-sa" type="range" min="1" max="10" value="2" step="0.5" style="width:100%;
accent-color:#2563eb;">
</div>
<div style="padding-left:5px;">
<div style="color:#ea580c;
font-weight:bold; margin-bottom:10px; white-space:nowrap;">🟠 กองทุน B (Orange)</div>
<div style="display:flex;
justify-content:space-between; font-size:12px;">
<span>Mean (กำไร): <b id="${uid}-val-mb">12</b>%</span>
</div>
<input id="${uid}-sl-mb" type="range" min="0" max="25" value="12" step="0.5" style="width:100%;
accent-color:#ea580c;">
<div style="display:flex; justify-content:space-between; font-size:12px;
margin-top:5px;">
<span>Risk (SD): <b id="${uid}-val-sb">5</b>%</span>
</div>
<input id="${uid}-sl-sb" type="range" min="1" max="10" value="5" step="0.5" style="width:100%;
accent-color:#ea580c;">
</div>
</div>
<div style="width:100%; background:#e0e7ff; padding:15px; border-radius:12px;
border:1px solid #c7d2fe;">
<div style="display:flex; justify-content:space-between; align-items:center;
margin-bottom:5px;">
<span style="font-weight:bold; color:#3730a3; font-size:14px;
white-space:nowrap;">
🤢 ระดับความกลัวความเสี่ยง (Risk Aversion: A)
</span>
<span id="${uid}-val-risk" style="font-weight:bold;
font-size:18px; color:#3730a3;">3.0</span>
</div>
<input id="${uid}-sl-risk" type="range" min="0" max="10" value="3" step="0.1" style="width:100%;
accent-color:#4338ca;">
<div style="display:flex; justify-content:space-between; font-size:11px;
color:#6366f1;">
<span>0 = กล้าได้กล้าเสีย (Risk Neutral)</span>
<span>10 = ขี้กลัวสุดๆ (High Risk Aversion)</span>
</div>
</div>
<div style="display:flex;
gap:15px; width:100%;">
<div id="${uid}-card-a" style="flex:1; padding:15px; border-radius:12px; border:2px solid #e2e8f0; text-align:center;
transition:0.3s;">
<div style="font-size:14px;
color:#64748b;">Utility Score A</div>
<div id="${uid}-score-a" style="font-size:24px; font-weight:bold;
color:#2563eb;">0</div>
</div>
<div id="${uid}-card-b" style="flex:1;
padding:15px; border-radius:12px; border:2px solid #e2e8f0; text-align:center; transition:0.3s;">
<div style="font-size:14px;
color:#64748b;">Utility Score B</div>
<div id="${uid}-score-b" style="font-size:24px; font-weight:bold;
color:#ea580c;">0</div>
</div>
</div>
<div id="${uid}-winner" style="font-weight:bold;
font-size:18px; color:#15803d; min-height:27px;"></div>
<div style="font-size:12px; color:#94a3b8; width:100%;">
*สูตรคำนวณ Utility: <b>U = Mean - 0.5 × A × Variance</b>
</div>
</div>`;
// --- Logic ---
const canvas = container.querySelector("canvas");
const ctx = canvas.getContext("2d");
// Inputs
const slMA = container.querySelector(`#${uid}-sl-ma`);
const slSA = container.querySelector(`#${uid}-sl-sa`);
const slMB = container.querySelector(`#${uid}-sl-mb`);
const slSB = container.querySelector(`#${uid}-sl-sb`);
const slRisk = container.querySelector(`#${uid}-sl-risk`);
// Displays
const dMA = container.querySelector(`#${uid}-val-ma`);
const dSA = container.querySelector(`#${uid}-val-sa`);
const dMB = container.querySelector(`#${uid}-val-mb`);
const dSB = container.querySelector(`#${uid}-val-sb`);
const
dRisk = container.querySelector(`#${uid}-val-risk`);
const scA = container.querySelector(`#${uid}-score-a`);
const scB = container.querySelector(`#${uid}-score-b`);
const cardA = container.querySelector(`#${uid}-card-a`);
const cardB = container.querySelector(`#${uid}-card-b`);
const elWinner = container.querySelector(`#${uid}-winner`);
// Scale Range (-20 to 40)
const MIN_X = -20;
const MAX_X = 40;
function getX(val) {
return ((val - MIN_X) / (MAX_X - MIN_X)) * width;
}
function drawNormal(mean, sd, color, fillColor) {
ctx.beginPath();
ctx.strokeStyle = color;
ctx.lineWidth = 3;
for (let x = MIN_X; x <= MAX_X; x += 0.2) {
const p = (1 / (sd * Math.sqrt(2 * Math.PI))) * Math.exp(-0.5 * Math.pow((x - mean) / sd, 2));
const plotY = height - 30 - (p * 1000);
const plotX = getX(x);
if (x === MIN_X) ctx.moveTo(plotX, plotY);
else ctx.lineTo(plotX, plotY);
}
ctx.stroke();
ctx.lineTo(getX(MAX_X), height-30);
ctx.lineTo(getX(MIN_X), height-30);
ctx.fillStyle = fillColor;
ctx.fill();
ctx.beginPath();
ctx.moveTo(getX(mean), height - 30);
ctx.lineTo(getX(mean), height - 250);
ctx.setLineDash([5, 5]);
ctx.stroke();
ctx.setLineDash([]);
}
function drawLegend(ma, sa, mb, sb) {
ctx.fillStyle = "rgba(255, 255, 255, 0.8)";
ctx.fillRect(10, 10, 200, 70);
ctx.strokeStyle = "#cbd5e1";
ctx.lineWidth = 1;
ctx.strokeRect(10, 10, 200, 70);
ctx.fillStyle = "#2563eb";
// Blue
ctx.beginPath(); ctx.arc(25, 30, 6, 0, Math.PI*2); ctx.fill();
ctx.font = "bold 14px sans-serif";
ctx.fillStyle = "#1e293b";
ctx.fillText(`กองทุน A: Mean=${ma}, SD=${sa}`, 40, 35);
ctx.fillStyle = "#ea580c"; // Orange
ctx.beginPath(); ctx.arc(25, 55, 6, 0, Math.PI*2);
ctx.fill();
ctx.font = "bold 14px sans-serif";
ctx.fillStyle = "#1e293b";
ctx.fillText(`กองทุน B: Mean=${mb}, SD=${sb}`, 40, 60);
}
function update() {
const ma = parseFloat(slMA.value);
const sa = parseFloat(slSA.value);
const mb = parseFloat(slMB.value);
const sb = parseFloat(slSB.value);
const riskA = parseFloat(slRisk.value);
dMA.innerText = ma; dSA.innerText = sa;
dMB.innerText = mb; dSB.innerText = sb;
dRisk.innerText = riskA.toFixed(1);
ctx.clearRect(0,0,width,height);
ctx.beginPath();
ctx.moveTo(0, height-30);
ctx.lineTo(width, height-30);
ctx.strokeStyle = "#94a3b8";
ctx.lineWidth = 1;
ctx.stroke();
ctx.beginPath();
ctx.moveTo(getX(0), 0);
ctx.lineTo(getX(0), height);
ctx.strokeStyle = "#e2e8f0";
ctx.lineWidth = 1;
ctx.stroke();
drawNormal(ma, sa, "#2563eb", "rgba(37, 99, 235, 0.2)");
drawNormal(mb, sb, "#ea580c", "rgba(234, 88, 12, 0.2)");
drawLegend(ma, sa, mb, sb);
const varA = sa * sa;
const varB = sb * sb;
const uA = ma - 0.5 * riskA * varA;
const uB = mb - 0.5 * riskA * varB;
scA.innerText = uA.toFixed(2);
scB.innerText = uB.toFixed(2);
cardA.style.borderColor = "#e2e8f0";
cardA.style.background = "white";
cardB.style.borderColor = "#e2e8f0"; cardB.style.background = "white";
if (uA > uB) {
elWinner.innerHTML = "🏆 แนะนำลูกค้า: <b>เลือกกองทุน A</b>";
cardA.style.borderColor = "#2563eb";
cardA.style.background = "#eff6ff";
} else if (uB > uA) {
elWinner.innerHTML = "🏆 แนะนำลูกค้า: <b>เลือกกองทุน B</b>";
cardB.style.borderColor = "#ea580c";
cardB.style.background = "#fff7ed";
} else {
elWinner.innerHTML = "⚖️ เลือกกองไหนก็ได้ (คุ้มค่าเท่ากัน)";
}
}
[slMA, slSA, slMB, slSB, slRisk].forEach(el => el.addEventListener("input", update));
update();
return container;
})()ตัวอย่างเกณฑ์ค่าเฉลี่ย–ความแปรปรวน
viewof N1 = Inputs.range([10, 30], { step: 1, value: 10, label: "N" })
viewof mu_a = Inputs.number({label: "Mean (μₐ)%", value: 5, step: 0.1})
viewof mu_b = Inputs.number({label: "Mean (μᵦ)%", value: 4, step: 0.1})
viewof var_a = Inputs.number({label: "Variance (σ²ₐ)", value: 3, step: 0.1})
viewof var_b = Inputs.number({label: "Variance (σ²ᵦ)", value: 5, step: 0.1})ข้อควระวัง
✈️ Survivorship Bias: The Hidden Data
บทเรียน: เราเห็นแต่รูที่ปีก เพราะเครื่องที่โดนยิงที่ปีก บินกลับมาได้
แต่เครื่องที่โดนยิงที่ เครื่องยนต์ (สีเขียว) ตกไปหมดแล้ว เราจึงไม่เห็นข้อมูลนั้น
Anscombe’s Quartet (กราฟสำคัญกว่าตัวเลข)
Select Data:
Statistical Summary
| Stat | Value |
|---|---|
| Mean X | |
| Mean Y | |
| Corr. | 0.816 |
Plot.plot({
height: 550, // ปรับความสูงให้พอดีสไลด์
width: 700,
grid: true,
marks: [
Plot.linearRegressionY(filtered, {x: "x", y: "y", stroke: "red", strokeWidth: 4}),
Plot.dot(filtered, {x: "x", y: "y", fill: "steelblue", r: 10}),
Plot.ruleX([0]),
Plot.ruleY([0])
],
x: {domain: [0, 20], label: "Variable X"},
y: {domain: [0, 14], label: "Variable Y"},
style: {fontSize: "18px", backgroundColor: "white"}
})References
- Devore, J. L. (2019). Probability and statistics for engineering and the sciences (9th ed.). Cengage Learning.
- Ross, S. M. (2020). Introduction to probability and statistics for engineers and scientists (6th ed.). Academic Press.
- Montgomery, D. C., & Runger, G. C. (2021). Applied statistics and probability for engineers (7th ed.). Wiley.
- Rice, J. A. (2006). Mathematical statistics and data analysis (3rd ed.). Cengage Learning.
- Wasserman, L. (2004). All of statistics: A concise course in statistical inference. Springer.