Pre-test: Decision Tree with Orange Data Mining
The Car Evaluation Dataset (1997) is a classic dataset used in machine learning and data analysis, especially for classification tasks. It was originally derived from a decision model created to evaluate car purchases based on specific criteria. This dataset is available from the UCI Machine Learning Repository.
1 Features of the Dataset
The Car Evaluation dataset contains six input attributes (features) and one target variable. The features are categorical, making it suitable for decision trees, random forests, and other classification algorithms.
2 Features (Attributes)
- Buying: The price of the car from the perspective of the buyer. It has 4 possible values:
vhigh: very highhigh: highmed: mediumlow: low
- Maint (Maintenance): The cost of maintaining the car. It also has 4 possible values:
vhigh: very highhigh: highmed: mediumlow: low
- Doors: The number of doors the car has. It has 4 possible values:
2: 2 doors3: 3 doors4: 4 doors5more: 5 or more doors
- Persons: The capacity of the car in terms of passengers. It has 3 possible values:
2: 2 persons4: 4 personsmore: more than 4 persons
- Lug_boot: The size of the luggage boot. It has 3 possible values:
small: smallmed: mediumbig: big
- Safety: The safety level of the car. It has 3 possible values:
low: low safetymed: medium safetyhigh: high safety
3 Target Variable
- Class (Car evaluation): The final evaluation of the car based on the attributes mentioned above. It has 4 possible values:
unacc: unacceptableacc: acceptablegood: goodvgood: very good
4 Example Record in the Dataset:
| Buying | Maint | Doors | Persons | Lug_boot | Safety | Class |
|---|---|---|---|---|---|---|
| vhigh | vhigh | 2 | 2 | small | low | unacc |
| low | low | 4 | more | big | high | vgood |
5 Objective
The goal of analyzing this dataset is typically to predict the “Class” of a car (whether it is unacceptable, acceptable, good, or very good) based on its attributes like price, maintenance cost, number of doors, safety, etc.
To interpret results from the Car Evaluation Dataset using a decision tree, we follow the same principles as interpreting any decision tree, with a specific focus on the categorical features and target classes in this dataset. Let’s break down the steps using an example decision tree trained on this data.
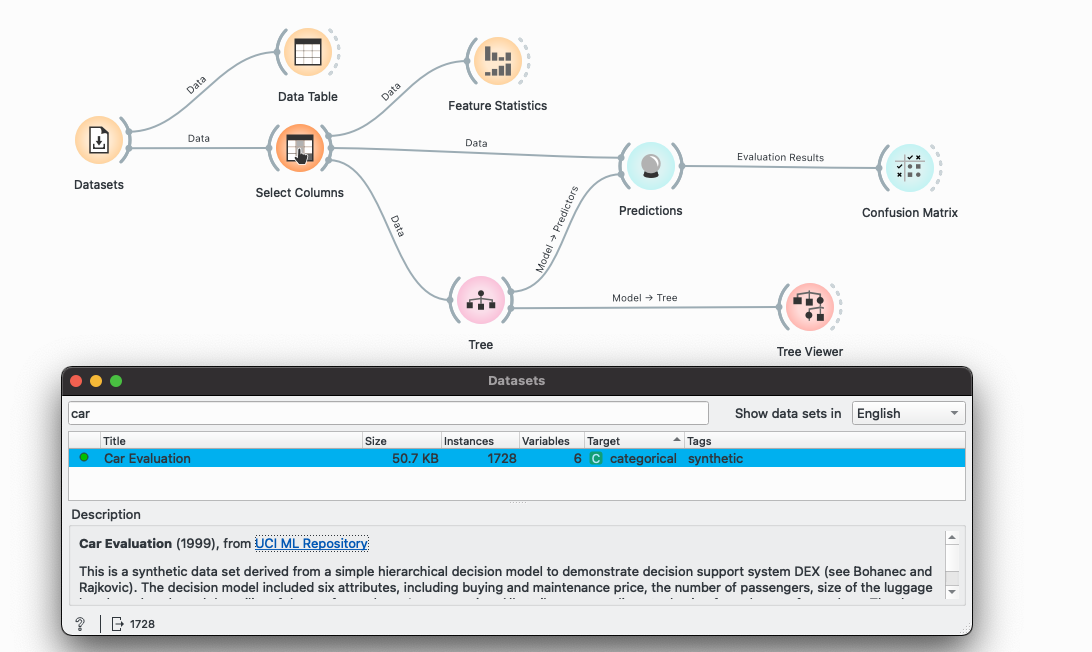
- How many observations or instances
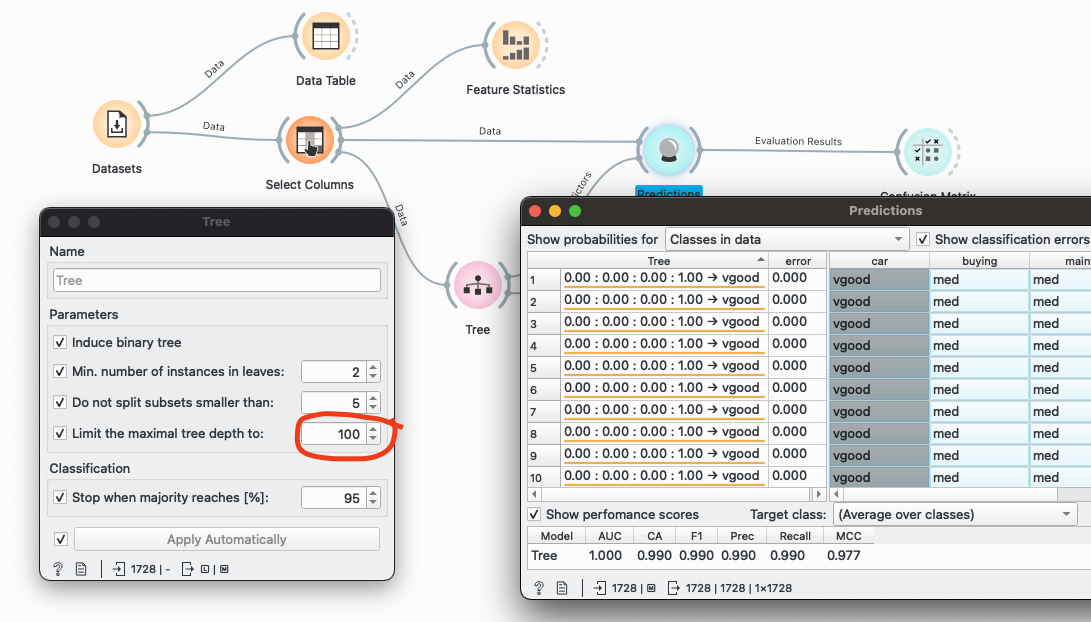
- Use all features to classify the target car, and double-click on the tree widget. What is the minimum tree depth required to achieve a classification accuracy (CA) greater than 0.90?
 3) Classification with Tree.
3) Classification with Tree.
If Person equal 5 and safety is low, What is the prediction from tree
If Person equal 5, safety is high, buying is high, and maint is vhigh. What is the prediction from tree?
If Person equal 5, safety is high, buying is high, and maint is high, log_boot is small, and safety is high. What is the prediction from tree?
6 The confusion matrix
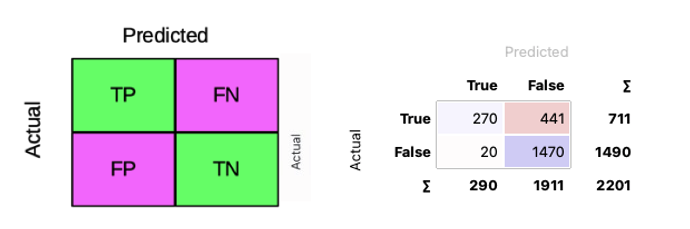
Accuracy: Accuracy in classification problems is the number of correct predictions made by the model over all kinds predictions made.
\[AC =\dfrac{TP+TN}{TP+FP+FN+TN} \]
What is the value of CA (3 decimals)
Pecision:
\[Prec =\dfrac{TP}{TP+FP}\] What is the value of Precision (3 decimals)
Recall:
\[Recall = \dfrac{TP}{TP+FN}\] What is the value of Recall (3 decimals)
F1 score:
\[F1 = \dfrac{2(Precision)(Recall)}{Precision+Recall}\]
What is the value of F1 (3 decimals)